navis.synapse_similarity¶
Cluster neurons based on their synapse placement.
Distances score is calculated by calculating for each synapse of neuron A: (1) the (Euclidian) distance to the closest synapse in neuron B and (2) comparing the synapse density around synapse A and B. This is type-sensitive: presynapses will only be matched with presynapses, post with post, etc. The formula is described in Schlegel et al., eLife (2017):
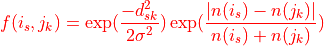
The synapse similarity score for neurons i and j being the average of
 over all synapses s of i. Synapse k is the
closest synapse of the same sign (pre/post) in neuron j to synapse s.
over all synapses s of i. Synapse k is the
closest synapse of the same sign (pre/post) in neuron j to synapse s.
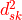 is the Euclidian distance between these distances.
Variable
is the Euclidian distance between these distances.
Variable  (
(sigma) determines what distance between s and k is considered “close”.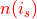 and
and 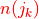 are
defined as the number of synapses of neuron i/j that are within given
radius
are
defined as the number of synapses of neuron i/j that are within given
radius  (
(omega) of synapse s and j, respectively (same sign only). This esnures that in cases of a strong disparity between and , the synapse similarity will be
close to zero even if the distance between s and k is very small.- Parameters:
x (NeuronList) – Neurons to compare. Must have connectors.
sigma (int | float) – Distance between synapses that is considered to be “close”.
omega (int | float) – Radius over which to calculate synapse density.
mu_score (bool) – If True, score is calculated as mean between A->B and B->A comparison.
restrict_cn (int | list | None) – Restrict to given connector types. Must map to a type, relation or label column in the connector tables. If None, will use all connector types. Use either single integer or list. E.g.
restrict_cn=[0, 1]to use only pre- and postsynapses.n_cores (int) – Number of parallel processes to use. Defaults to half the available cores.
- Return type:
pandas.DataFrame
See also
navis.synblast()NBLAST variant using synapses.
Examples
>>> import navis >>> nl = navis.example_neurons(5) >>> scores = navis.synapse_similarity(nl, omega=5000/8, sigma=2000/8)